-

-
KNIME
- 软件大小:645.00MB
- 软件类型:国产软件
- 软件分类:开发软件
- 软件语言:简体中文
- 软件授权:免费软件
- 支持系统:Mac
 KNIME MAC版是一款功能强大的开源数据挖掘软件,KNIME
MAC最新版可以帮助用户创建数据分析源,还可以选择性的运行某一段步骤,适用性极广,并具有丰演的开源的数据集成,数据处理,数据分析和数据勘探等功能,KNIME
MAC版通过内存内流传输和多线程数据处理来扩展工作流性能。
KNIME MAC版是一款功能强大的开源数据挖掘软件,KNIME
MAC最新版可以帮助用户创建数据分析源,还可以选择性的运行某一段步骤,适用性极广,并具有丰演的开源的数据集成,数据处理,数据分析和数据勘探等功能,KNIME
MAC版通过内存内流传输和多线程数据处理来扩展工作流性能。
软件介绍
KNIME for Mac给了用户有能力以可视化的方式创建数据流或数据通道,可选择性 地运行一些或全部的分析步骤,并以后面研究结果,模型 以及 可交互的视图。
KNIME 由Java写成,其基于 Eclipse 并通过插件的方式来提供更多的功能。通过以插件的文件,用户可以为文件,图片,和时间序列加入处理模块,并可以集成到其它各种各样的开源项目中,比如:R 语言,Weka,Chemistry Development Kit 和 LibSVM。
软件特色
1、采用完全图型化的操作方式
2、支持各类方式的数据加载,包括文件、数据库等
3、支持各类数据处理方式,包括按列(如分拆、合并等)、按行(过滤、变形)、矩阵(转置)和PMML(字段投影、一对多、多对一、正态化、反正态化等)
4、支持各类数据视图,如点图、直方图、饼图、分布图
5、支持假设检验和回归方法
6、支持决策树、贝叶斯、聚类、规则推导、神经网络等挖掘方法
7、支持流程控制
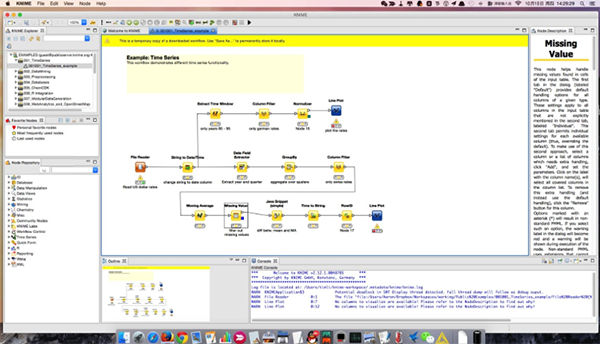
功能介绍
1、构建端到端的数据科学工作流程
用直观的拖放式图形界面创建可视化工作流,不需要编码。
将不同领域的工具与KNIME原生节点融合在一个工作流中,包括R和Python的脚本,机器学习,或与Apache Spark的连接。
从2000多个模块("节点")中选择,建立你的工作流程。对你的分析的每一步进行建模,控制数据流,并确保你的工作始终是最新的。
快速启动和运行。从数百个公开可用的工作流程范例中选择一个,或使用集成的工作流程教练来指导你建立你的工作流程。
2、混合来自任何来源的数据
打开并结合简单的文本格式(CSV、PDF、XLS、JSON、XML等)、非结构化数据类型(图像、文件、网络、分子等)或时间序列数据。
连接到大量的数据库和数据仓库,整合来自Oracle、Microsoft SQL、Apache Hive等的数据。从HDFS、S3或Azure加载Avro、Parquet或ORC文件。
从Twitter、AWS S3、Google Sheets和Azure等来源访问和检索数据。
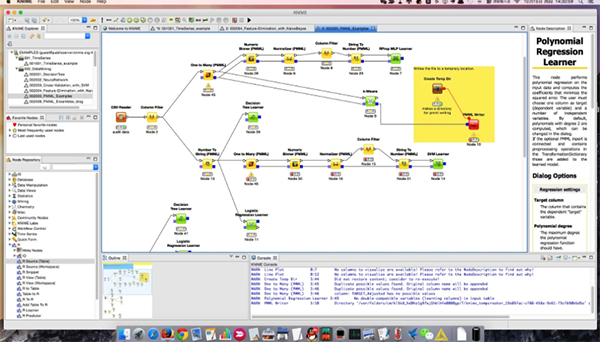
3、塑造你的数据
得出统计数据,包括平均值、量值和标准差,或应用统计测试来验证一个假设。将降维、相关分析等整合到你的工作流程中。
在您的本地机器、数据库内或分布式大数据环境中对数据进行汇总、排序、过滤和连接。
通过规范化、数据类型转换和缺失值处理来清理数据。通过离群值和异常检测算法检测超出范围的值。
提取和选择特征(或构建新的特征),为机器学习准备你的数据集。操作文本,在数字数据上应用公式,并应用规则来过滤掉或标记样本。
4、充分利用机器学习和人工智能
使用先进的算法,包括深度学习、基于树的方法和逻辑回归,为分类、回归、降维或聚类建立机器学习模型。
通过超参数优化、提升、装袋、堆叠或构建复杂的组合来优化模型性能。
通过应用性能指标验证模型,包括准确度、R2、AUC和ROC。进行交叉验证以保证模型的稳定性。
直接使用验证过的模型进行预测,或使用业界领先的PMML,包括在Apache Spark上。
5、发现和分享洞察力
用经典的(柱状图、散点图)以及高级的图表(平行坐标、太阳花、网络图)来可视化数据,并根据你的需要进行定制。
在KNIME表中显示有关列的汇总统计,并过滤掉任何不相关的东西。
将报告导出为PDF、Powerpoint或其他格式,用于向利益相关者展示结果。
将处理过的数据或分析结果存储在许多常见的文件格式或数据库中。
6、根据需求扩大执行规模
建立工作流程原型,探索各种分析方法。检查和保存中间结果,以确保快速反馈和有效发现新的、创造性的解决方案。
通过内存流和多线程数据处理来扩展工作流程的性能。
在Apache Spark上锻炼数据库内处理或分布式计算的能力,以进一步提高计算性能。
版本:V3.6.1 | 更新时间:2022-04-27





