-

-
Zotero Connector
- 软件大小:90.83MB
- 软件类型:国产软件
- 软件分类:杂类工具
- 软件语言:简体
- 软件授权:免费软件
- 支持系统:WinAll
 Zotero Connector官方版是一款实用性强的chrome文献资料管理工具,Zotero
Connector电脑版可以帮你把网页上的文献资料进行保存管理。Zotero提供了数千个网页的支持,用户可以将项目分类到集合中,并且可以使用关键字标记项目。
Zotero Connector官方版是一款实用性强的chrome文献资料管理工具,Zotero
Connector电脑版可以帮你把网页上的文献资料进行保存管理。Zotero提供了数千个网页的支持,用户可以将项目分类到集合中,并且可以使用关键字标记项目。
软件特色
1、Zotero Connector官方版支持对资料进行整理、归类
2、可以进行输出BibTex、小组分享
3、拥有强大的全文搜索功能
4、支持网页、博客、邮件、图片、视频等内容的收集
5、兼容性强
使用步骤
1.进入chrome扩展程序,解压你在本站下载的插件,并拖入扩展程序页即可。
2.最新版本的chrome浏览器直接拖放安装时会出现“程序包无效CRX-HEADER-INVALID”的报错信息,参照:Chrome插件安装时出现"CRX-HEADER-INVALID"解决方法,安装好后即可使用。
3.安装完毕后会在浏览器右上方出现Zotero Connector图标,
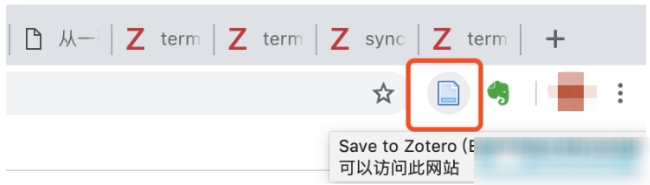
4.点击图标登入Zotero就可以使用了。
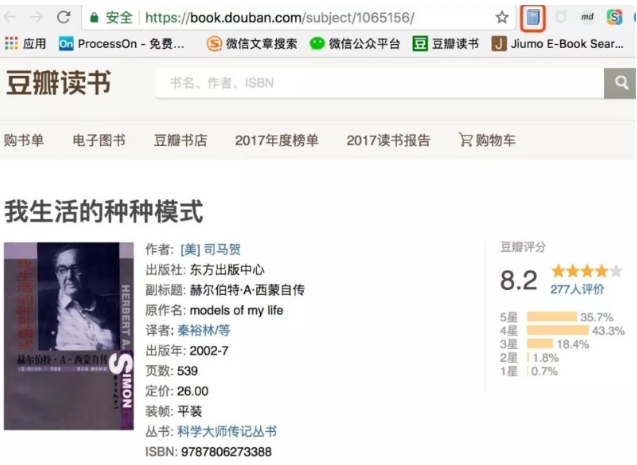
5.以豆瓣网站,《我生活的种种模式》为例,请特别注意,你的Chrome浏览器地址栏旁边会多出一个图书的标识!点击它,保存即可。
6.打开 Zotero 软件,我们会发现,之前鼠标定位的子类下面,会多出一个条目,如下图所示:更有趣的是,《我生活的种种模式》这本书的豆瓣网址直接保存下来了,下次直接点击即可。这就是 Zotero 极其强大的 Web Translators 功能,它可以根据世界上主要的信息资讯网站,生成相应的图标
比如,豆瓣的图书就是图书的小符号
7.导入 Google 学术,我们发现,这次浏览器的图标变成一个文件夹!这就意味着,有多篇文献识别出来,需要保存。
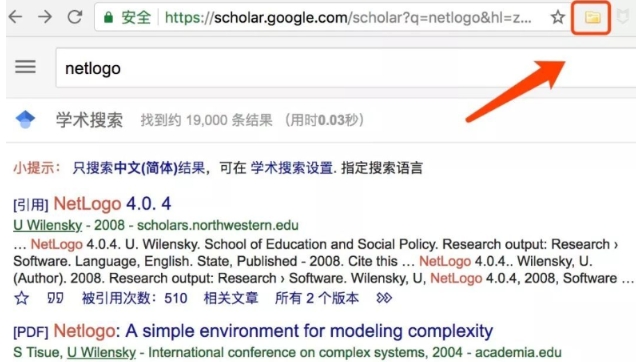
8.点击文件夹图标,然后弹出对话窗口,我们挑选一篇引用率排第一、带PDF文档的保存下来:
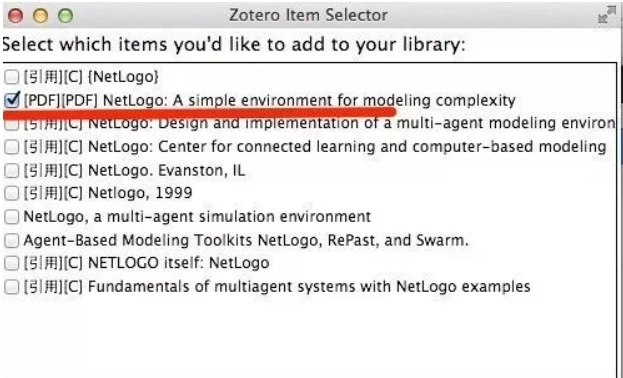
9.打开 Zotero 软件,我们会惊讶地发现:Google 学术里面带 PDF 文档,刚才弹出窗口提示有 PDF 字眼的,它连关联 PDF 也关联起来了!如下图所示:

10.除了保存网页,本地可能还有许多之前存下的文档,也可以加入 Zotero 中。例如,不少 PDF 文献,尤其是一些本来是从学术数据库下载的文献,它们支持 PDF 元数据功能,这样就非常省事,可以直接拖到 Zotero 中来,自动将其文献信息识别出来。如下图所示,我们将一个 PDF 文档拖到自己的项目文件夹中来,Zotero 会自动抓取元数据,如文档的条目类型、标题、作者等信息。(元数据已被抓取的 PDF 文档可以右键重新抓取元数据哦)这时候自动根据 PDF 元数据生成相关文献信息:

更新日志
LibreOffice 修复:修复了插入脚注的脚注标记问题(自 7.0.23 起)。此修复回滚了 7.0.23 版本中为解决在 LibreOffice 25.2+ 版本中插入富文本时发生的崩溃问题而进行的修复,但 LibreOffice 25.2.6 将很快发布并修复该问题。
合并相关项目问题修复:修复了合并相关项目后项目与自身相关的问题。
Mac 系统改进:
启动 / 显示文件时处理 Windows 绝对路径。
修复了 Google Docs 更改后 Safari 中不显示 “Edit with Zotero” 气泡的问题。
版本:官方版 v9.0.4 | 更新时间:2026-06-03





